
Rayven makes it easy to ingest, centralize, and work with data from any source — devices, systems, APIs, databases, and manual inputs. There are two primary methods to bring your data into the platform:

Data Ingestion Overview
Rayven.io supports two primary methods for bringing data into the platform, designed to accommodate both real-time event data and structured business records:
1. Real-Time + Event-Based Data (Cassandra)
Use Rayven’s Workflow Builder and protocol/system/API-level connectors to ingest high-frequency or streaming data into a Cassandra NoSQL database. Ideal for telemetry, logs, and time-series events.
-
Examples: device messages, webhook alerts, usage events
-
Tools: MQTT, Modbus, HTTP, webhook listeners, external system connectors
2. Structured Business Data (MySQL Tables)
Upload or manage static and relational data via Rayven’s Primary and Secondary Tables, powered by MySQL. These tables can be edited directly through the UI, populated via workflows, or ingested from file uploads.
-
Examples: customer records, inventory, orders, configuration values
-
Tools: File Upload Nodes, Table Write/Read/Update Nodes, manual editing in Table interface
This dual-database approach allows Rayven to handle everything from raw data streams to structured business logic in a unified environment.
1. Structured Data via Primary and Secondary Tables (MySQL)
Rayven allows you to manage your core business data using Primary and Secondary tables stored in a MySQL relational database.
What It’s Used For
-
Inventory and asset records
-
Product catalogs
-
Customer and order details
-
Device configurations
-
Asset registries
-
Lookup/reference tables
Table Types
Primary Tables: Foundational datasets central to the business logic.
Secondary Tables: Supplementary datasets linked to primary records.
Key Benefits
-
Clean relational structure (ideal for joins and querying)
-
Compatible with dashboards, reports, and business logic
-
Upload manually or via API
-
Two-way data interaction with workflows (input/output)
2. Unstructured and Event-Based Data via Connectors (Cassandra)
Use Rayven’s Workflow Builder with protocol-level, system-level, and API-level connectors for real-time or scheduled data ingestion.
What It’s Used For
-
Telemetry data (e.g., temperature, vibration, voltage)
-
Event logs and machine state changes
- Data from 3rd party software
-
Continuous sensor inputs
-
System notifications and syncs
Data is stored in a Cassandra NoSQL database optimized for high-speed, time-series/event data.
Key Benefits
-
Horizontal scalability for high-volume, high-frequency ingestion
-
Schema-flexible (supports semi-structured inputs)
-
Real-time analytics and alert triggers
-
Event-driven workflow integration
Integration Between Structured and Unstructured Data
Workflows can read/write to both MySQL and Cassandra, allowing:
-
Real-time alerts to update structured records
-
Merging static context (e.g., customer SLAs) with live telemetry
-
Feedback loops: push AI insights into business tables or external systems
Ready-to-Go Connectors
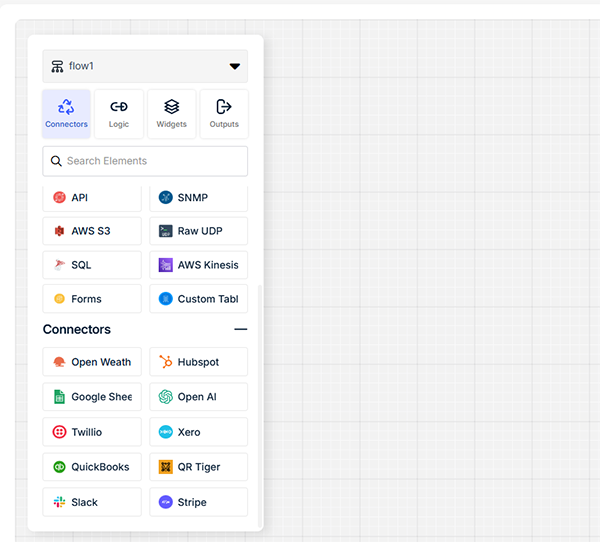
Rayven offers a wide range of pre-built connectors:
-
IoT protocols (MQTT, Modbus, OPC-UA, etc.)
-
Cloud system APIs (CRM, ERP, MES, Any Software System)
-
File uploads (CSV, JSON, XML)
-
Custom API and SDK connectors
Key Features
-
Real-time or scheduled ingestion
-
Drag-and-drop setup
-
Data transformation and validation support
-
Scales to thousands of concurrent data streams
Choosing the Right Ingestion Method
| Use Case | Best Option |
|---|---|
| Static or occasional uploads | Custom Tables |
| Continuous real-time ingestion | Workflow Toolkit |
| IoT device integrations | Protocol Connectors |
| Cloud system/API integrations | System/API Connectors |
Many solutions combine both — e.g., custom tables for master data + workflows for streaming IoT data.
Summary Table
| Ingestion Method | Data Type | Storage | Use Cases |
| Primary/Secondary Tables | Structured | MySQL | Business records, catalogs, configurations |
| Connectors via Workflow Builder | Real-time / Event-based | Cassandra | IoT telemetry, system alerts, API data |
Rayven’s dual-database approach ensures centralized, unified, and action-ready data ingestion — no matter the format or source.
Q&A
General Ingestion
Q: What are the main ways to bring data into Rayven?
A: Use MySQL-based Tables for structured data or Cassandra-based Workflows for event-based streaming.
Q: Can I ingest both static and live data?
A: Yes. Use structured tables for static/master data and workflows for continuous, time-based data.
Structured Data (MySQL)
Q: What are Primary and Secondary tables?
A: Primary tables store core business objects. Secondary tables add contextual or historical records.
Q: Can I update structured tables using workflows?
A: Yes. You can read from/write to tables using nodes in workflows.
Unstructured Data (Cassandra)
Q: What kind of data goes into Cassandra?
A: High-frequency, schema-flexible, real-time sensor or event data.
Q: Do connectors support third-party APIs?
A: Yes. Use API connectors to pull/push data from external platforms.
Q: Can I use both ingestion methods in the same solution?
A: Yes. Many applications use MySQL tables for master data and Cassandra for live data streams in parallel workflows.
Q: Can workflows push data back into external systems?
A: Yes. You can use HTTP POST, SQL, or API output nodes to sync data out of Rayven.
Example Workflows
1. Upload Asset Master Data
- File Upload Node (CSV: assets.csv)
- CSV Parse Node
- Table Write Node (Primary Table: Assets)2. Stream Sensor Telemetry to Cassandra
- MQTT Input Node
- Cassandra Write Node (Telemetry Table)3. Update Business Record Based on Alert
- MQTT Input Node (vibration sensor)
- Rule Node (vibration > 15)
- Table Update Node (Asset Table: status = 'alert')4. Combine Live and Static Data
- Table Read Node (Asset SLA)
- Cassandra Read Node (Sensor Temp)
- Join/Enrichment Node
- Dashboard Widget (Merged View)5. API Sync from External CRM
- HTTP GET Node (External CRM)
- JSON Parse Node
- Table Write Node (Customers Table)Below are examples of custom data templates and guidance for embedding connectors directly into your app workflows.
Custom Data Templates
Asset Registry Template (CSV)
asset_id,asset_name,type,location,status
AS001,Main Pump,Pump,Zone A,Active
AS002,Boiler Unit 2,Boiler,Zone B,MaintenanceCustomer Order Template (JSON)
{
"order_id": "ORD12345",
"customer_id": "CUST001",
"items": [
{ "product": "Valve", "qty": 3 },
{ "product": "Sensor", "qty": 2 }
],
"status": "shipped"
}Sensor Configuration Template (XML)
<device>
<id>Sensor-005</id>
<type>Temperature</type>
<threshold>80</threshold>
<unit>Celsius</unit>
</device>Embedding Connectors in App Flow
To embed connectors within your app logic using the Workflow Builder:
-
Drag a Connector Node into your workflow canvas (e.g., MQTT Input, HTTP GET).
-
Map incoming fields using the Transformation or JSON Parse Node.
-
Route parsed data to either:
-
A Table Write Node (for storing structured output)
-
A Cassandra Node (for storing time-series/event data)
-
AI or Rule Nodes for further decision logic
-
-
Trigger visual or backend responses, such as:
-
Update a dashboard widget
-
Send alerts (Email/SMS)
-
Call an external API via HTTP POST Node
-
These steps allow seamless integration of connectors with app-level logic and real-time processing.